
HDL 기반 시스템 반도체 설계 과정
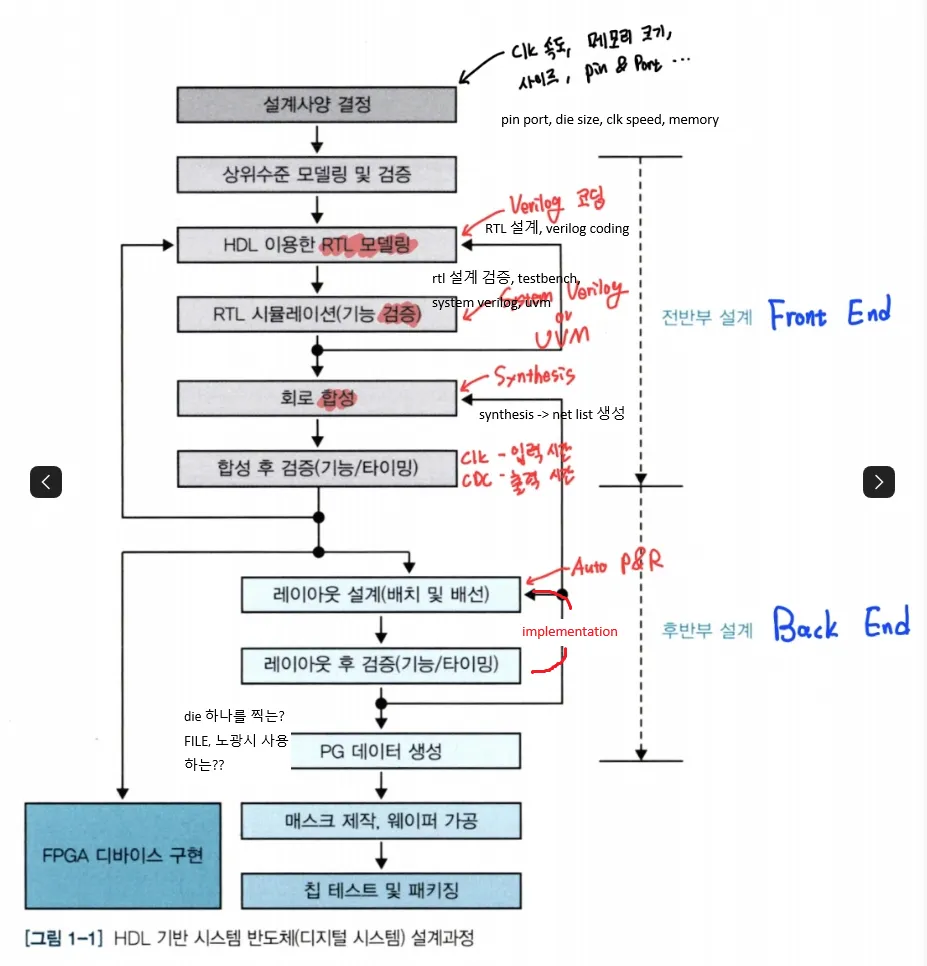
verilog compile 과정
verilog code (sw) -> (1) synthesis -> H/W circuit -> fpga implementation -> bitstream (fpga 등 h/w 회로 파일, xxx.bit)
-> synthesis 과정에서 net list가 생성됨
* net list : 정렬되지 않은 형태의 H/W 정보
(1) synthesis : verilog 코드를 design compiler를 이용해 gate-level netlist로 변환하는 과정
(2) implementation : gate, tr 상태에서의 회로 배치
gate
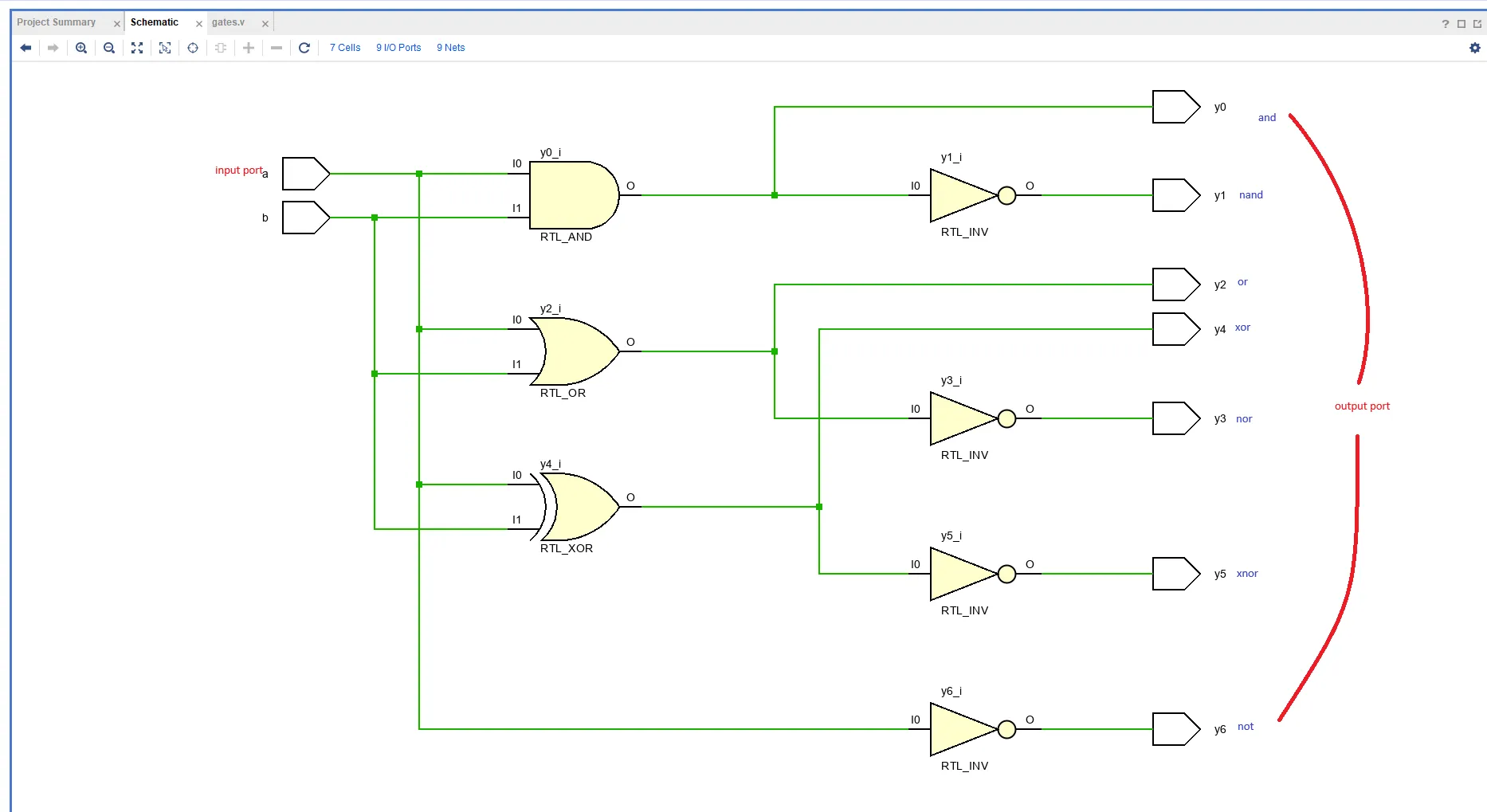
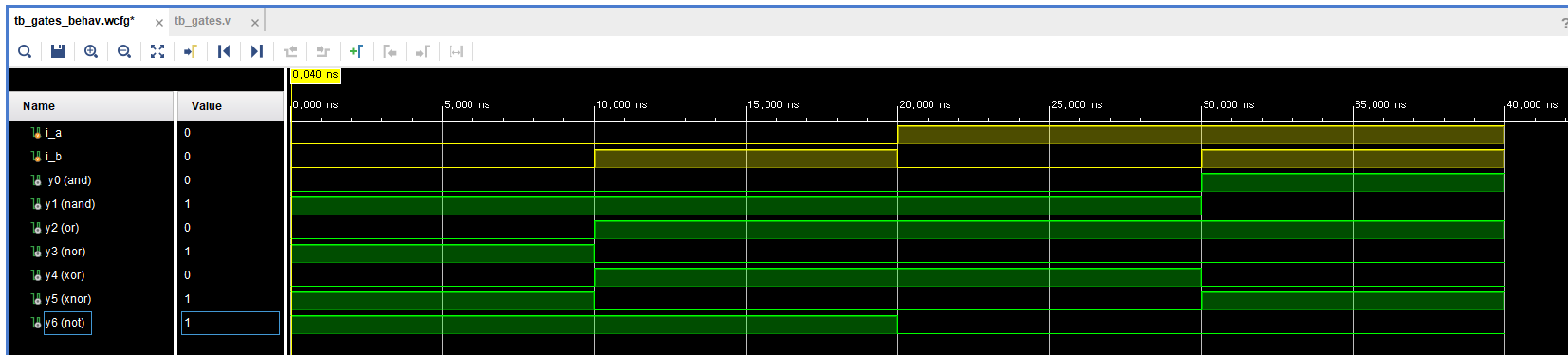
- gates.v - verilog code
and / nand / or / nor / xor / xnor / not gate 를 연속 할당문(continuous assignment) 으로 구현
`timescale 1ns / 1ps
module gates( // chip name
// port list
input a,
input b,
output y0,
output y1,
output y2,
output y3,
output y4,
output y5,
output y6
);
// circuit architecture
assign y0 = a & b; // and oper
assign y1 = ~ (a & b); // nand oper
assign y2 = a | b; // or oper
assign y3 = ~ (a | b); // nor oper
assign y4 = a ^ b; // xor oper
assign y5 = ~ (a ^ b); // exnor oper
assign y6 = ~ a;
endmodule
- RTL analysis
1) 코드가 gate level로 분석되어 출력되는 것을 확인할 수 있다
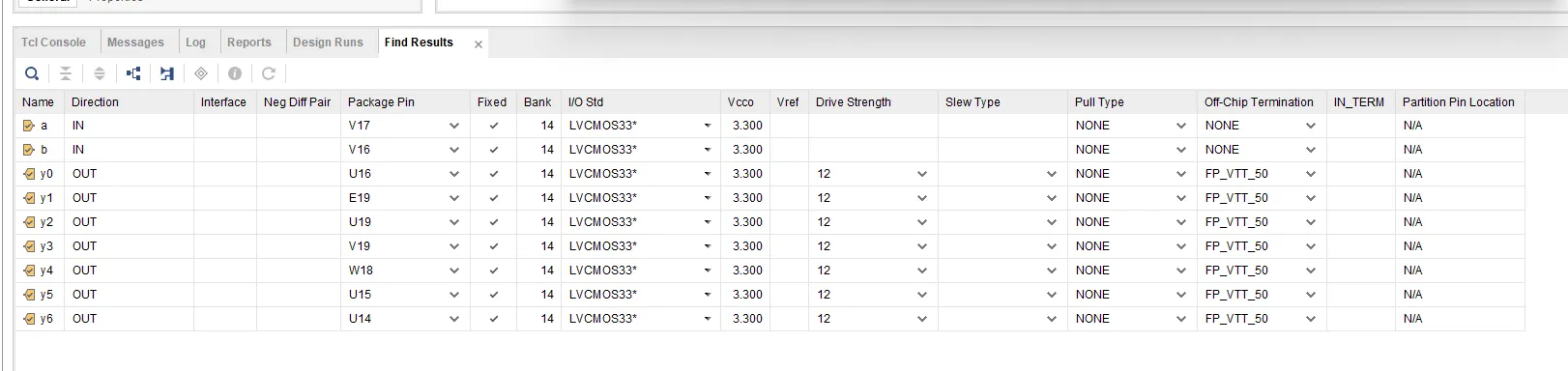
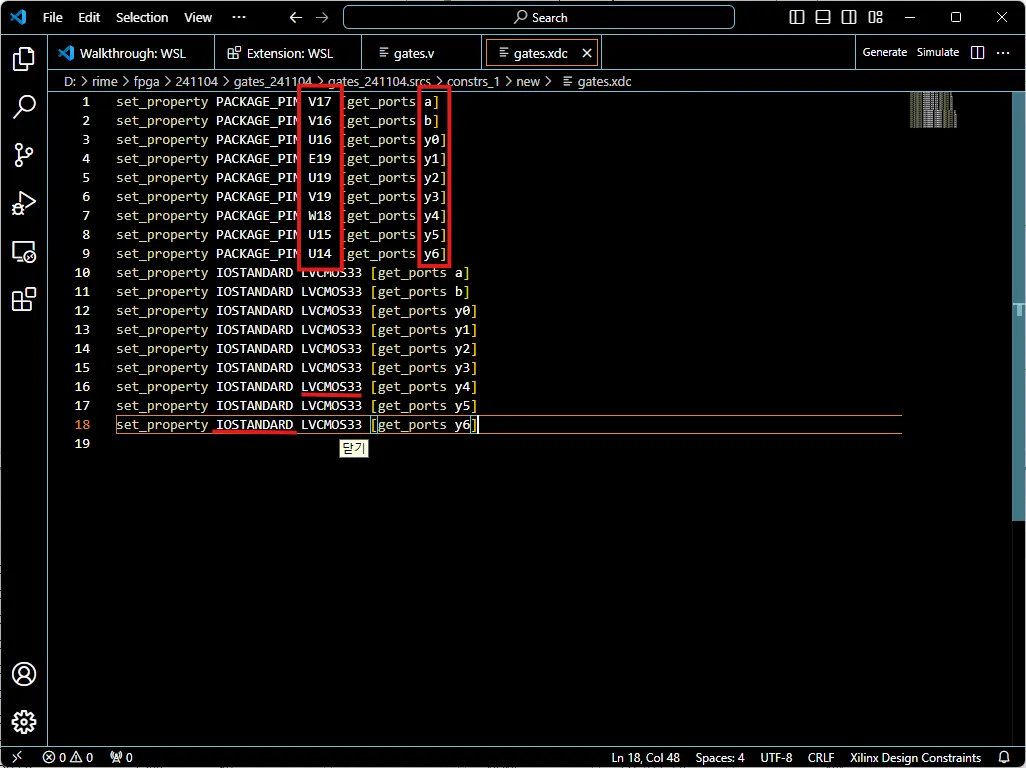
2) 보드에 올리기 위한 pin 설정
package pin, I/O std 설정 후 ctrl+s → xdc (constraint file) 생성
- testbench.v
`timescale 1ns / 1ps
module tb_gates();
reg a;
reg b;
wire y0;
wire y1;
wire y2;
wire y3;
wire y4;
wire y5;
wire y6;
gates dut( // dut(design under test, 관용어) -> 시뮬레이션 대상 instance, instanciation
.a(a), // .포트이름(변수)
.b(b),
.y0(y0),
.y1(y1),
.y2(y2),
.y3(y3),
.y4(y4),
.y5(y5),
.y6(y6)
);
initial begin
#00 a = 1'b0; b = 1'b0;
#10 a = 1'b0; b = 1'b1;
#10 a = 1'b1; b = 1'b0;
#10 a = 1'b1; b = 1'b1;
#10 $finish;
end
endmodule- simulation
🚩 verilog 변수 타입
- reg : 값을 저장 가능
- wire : 값을 저장할 수 X
half_adder
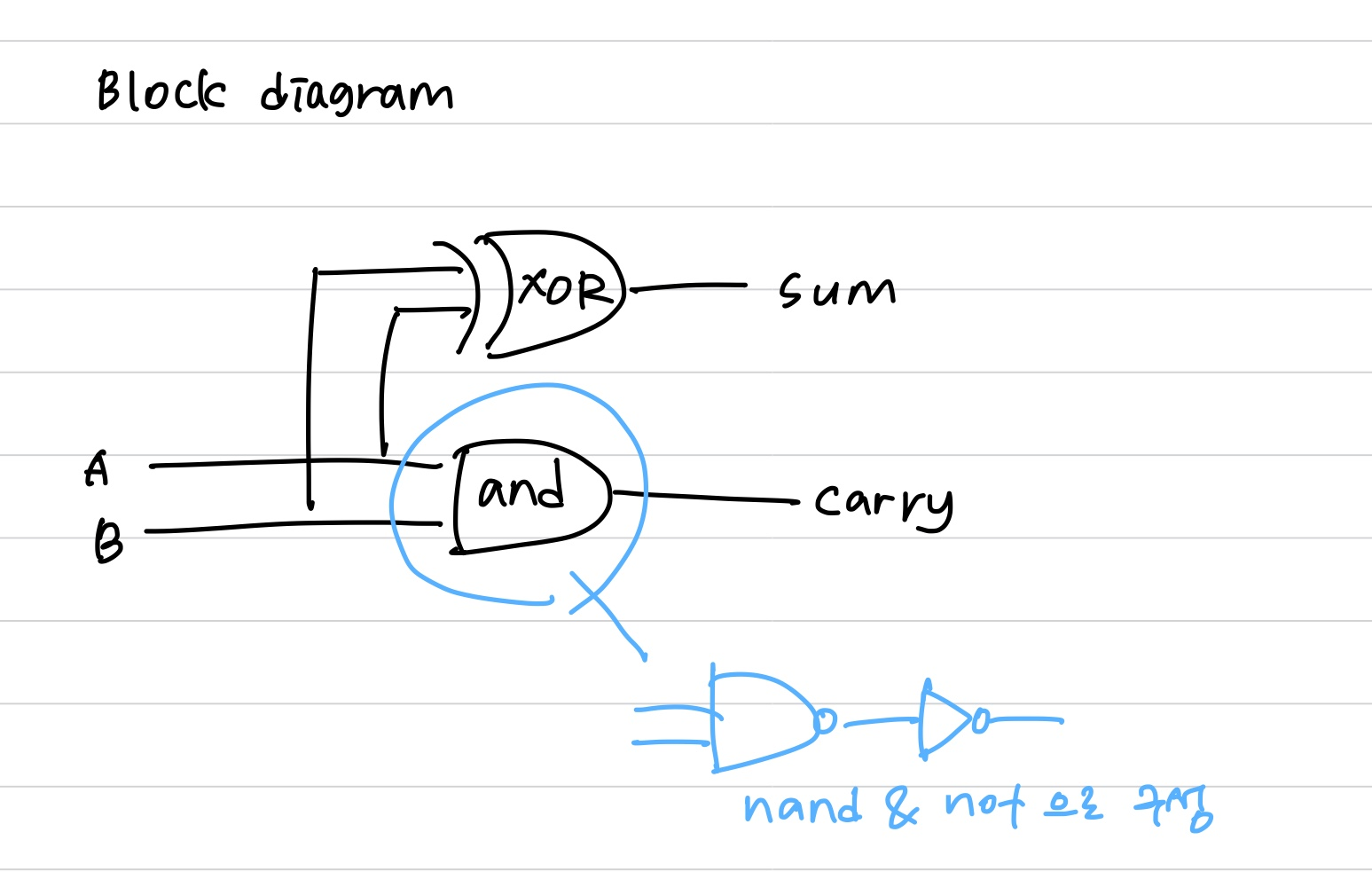
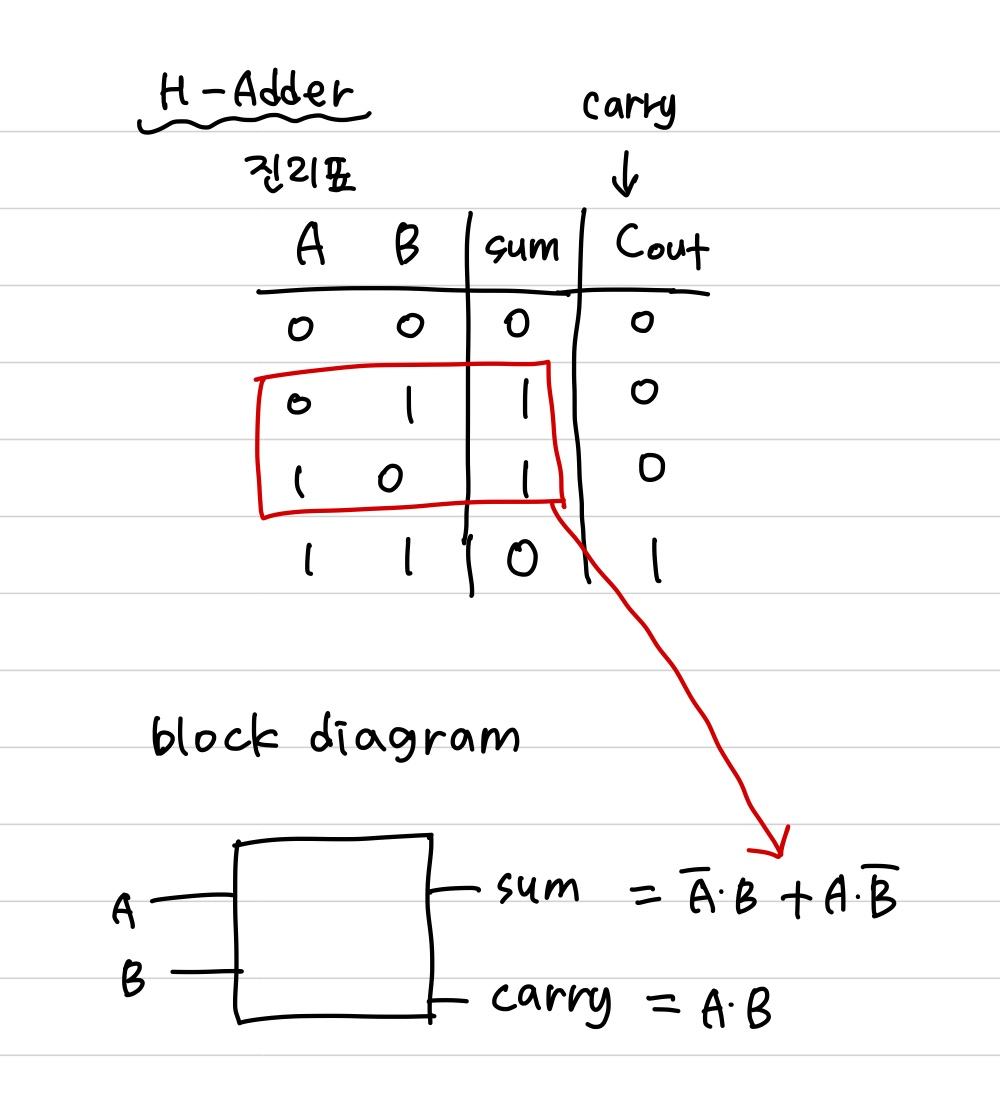
half adder는 1bit를 연산할 때 사용된다.
xor gate와 and gate를 이용해 sum과 carry를 출력한다.
- half_adder.v
`timescale 1ns / 1ps
module half_adder(
input wire i_a,
input wire i_b,
output sum,
output carry
);
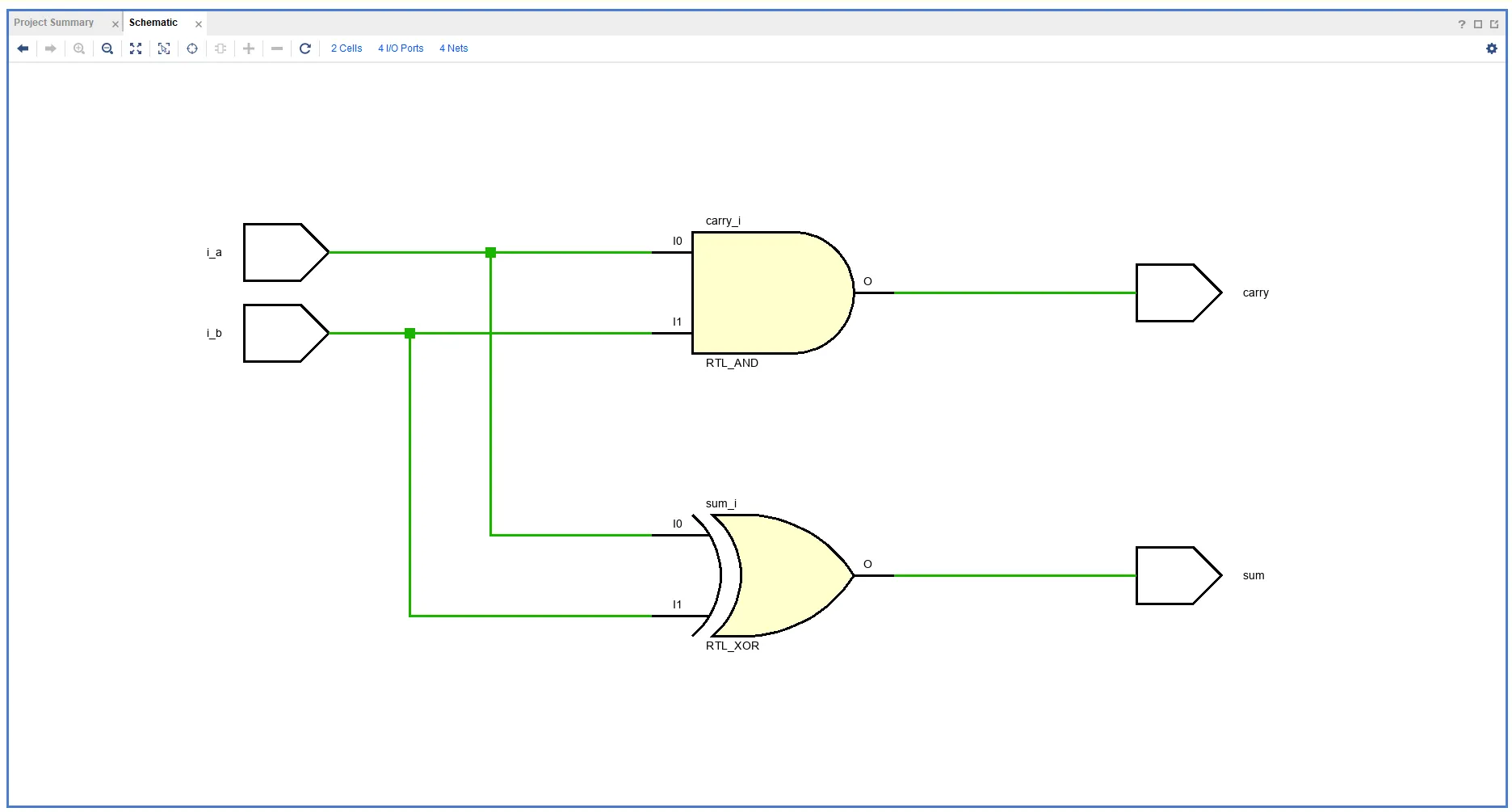
assign sum = i_a ^ i_b; // 연속할당문
assign carry = i_a & i_b;
endmodule- RTL Analysis
1bit full_adder
full adder는 1bit를 계산시 carry를 받아서 계산한다.
half adder 두개와 carry끼리 연산하는 or gate로 구성된다.
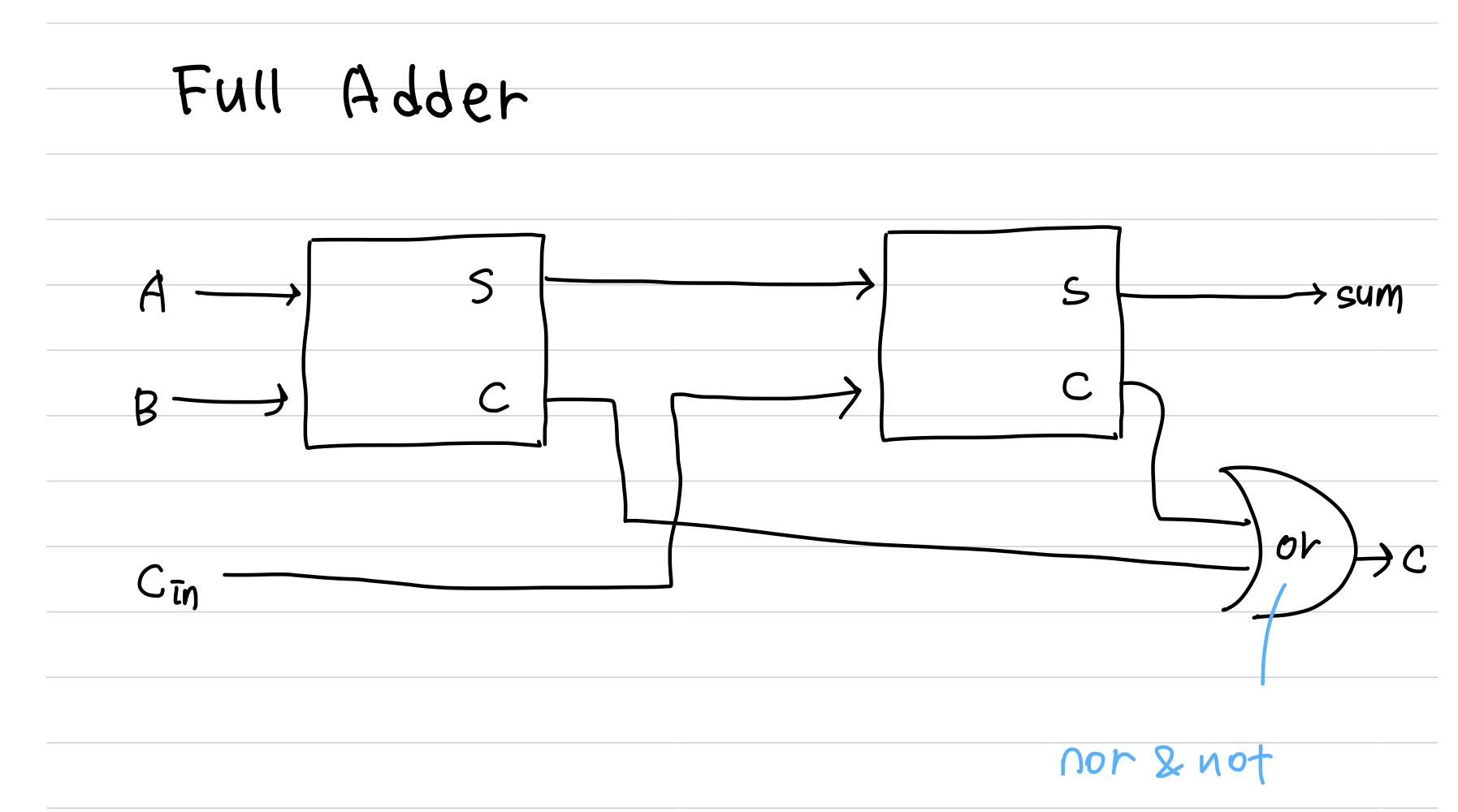
- full_adder.v
`timescale 1ns / 1ps
// full adder
module full_adder(
input i_fa_a,
input i_fa_b,
input i_cin,
output fa_sum_o,
output fa_carry_o
);
wire sum1, carry1, sum2, carry2;
half_adder U_HA1(
.i_a(i_fa_a),
.i_b(i_fa_b),
.ha_sum_o(sum1),
.ha_carry_o(carry1)
);
half_adder U_HA2(
.i_a(sum1),
.i_b(carry1),
.ha_sum_o(sum2),
.ha_carry_o(carry2)
);
assign fa_carry_o = carry1 | carry2;
assign sum = sum2;
endmodule
// half adder
module half_adder(
input i_a,
input i_b,
output ha_sum_o,
output ha_carry_o
);
assign ha_sum_o = i_a ^ i_b;
assign ha_carry_o = i_a & i_b;
endmodule
- RTL Analysis
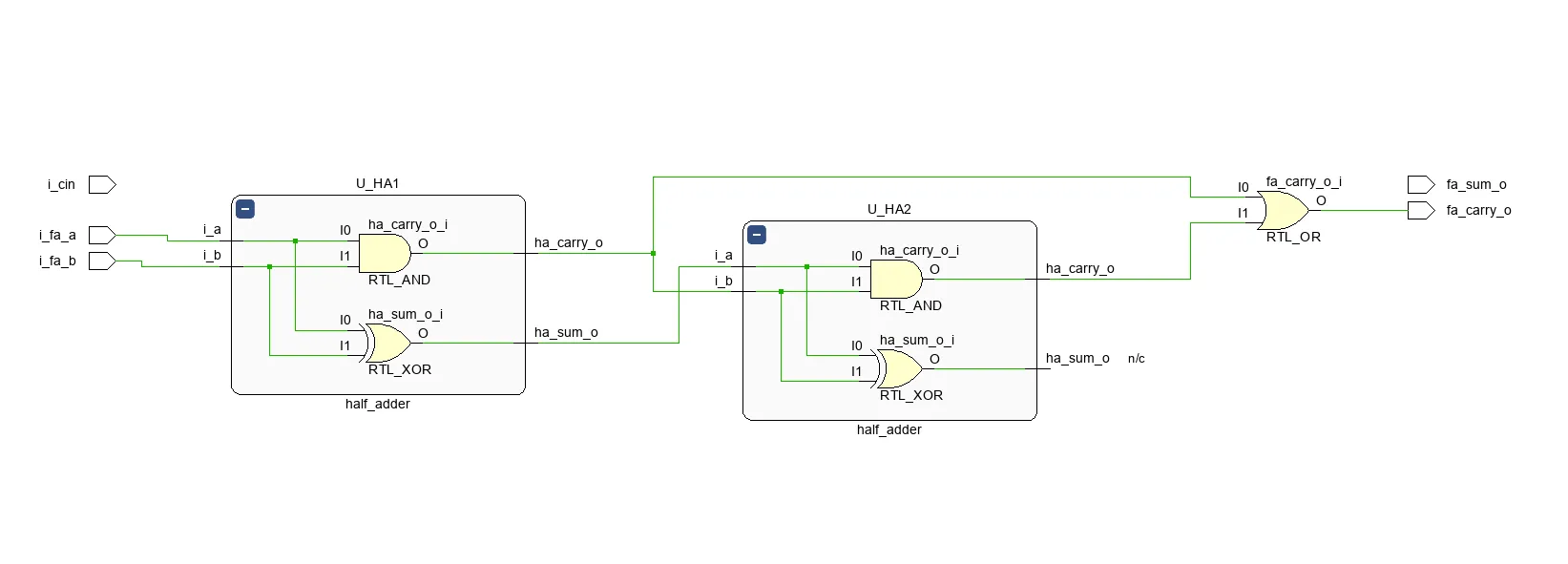
- testbench.v
`timescale 1ns / 10ps
module tb_adder();
reg i_fa_a;
reg i_fa_b;
reg i_cin;
wire fa_sum_o;
wire fa_carry_o;
full_adder dut(
.i_fa_a(i_fa_a),
.i_fa_b(i_fa_b),
.i_cin(i_cin),
.fa_sum_o(fa_sum_o),
.fa_carry_o(fa_carry_o)
);
initial begin
#00 i_cin = 0; i_fa_b = 0; i_fa_a = 0;
#10 i_cin = 0; i_fa_b = 0; i_fa_a = 1;
#10 i_cin = 0; i_fa_b = 1; i_fa_a = 0;
#10 i_cin = 0; i_fa_b = 1; i_fa_a = 1;
#10 i_cin = 1; i_fa_b = 0; i_fa_a = 0;
#10 i_cin = 1; i_fa_b = 0; i_fa_a = 1;
#10 i_cin = 1; i_fa_b = 1; i_fa_a = 0;
#10 i_cin = 1; i_fa_b = 1; i_fa_a = 1;
#10 $finish;
end
endmodule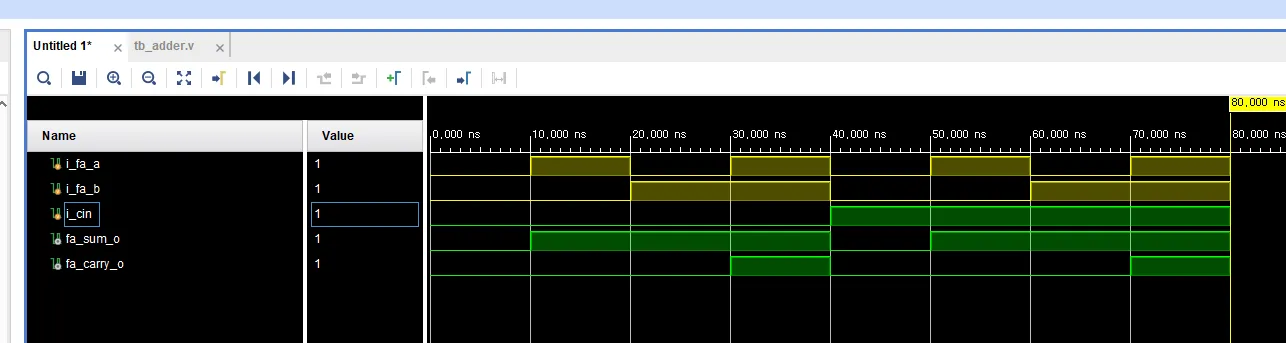
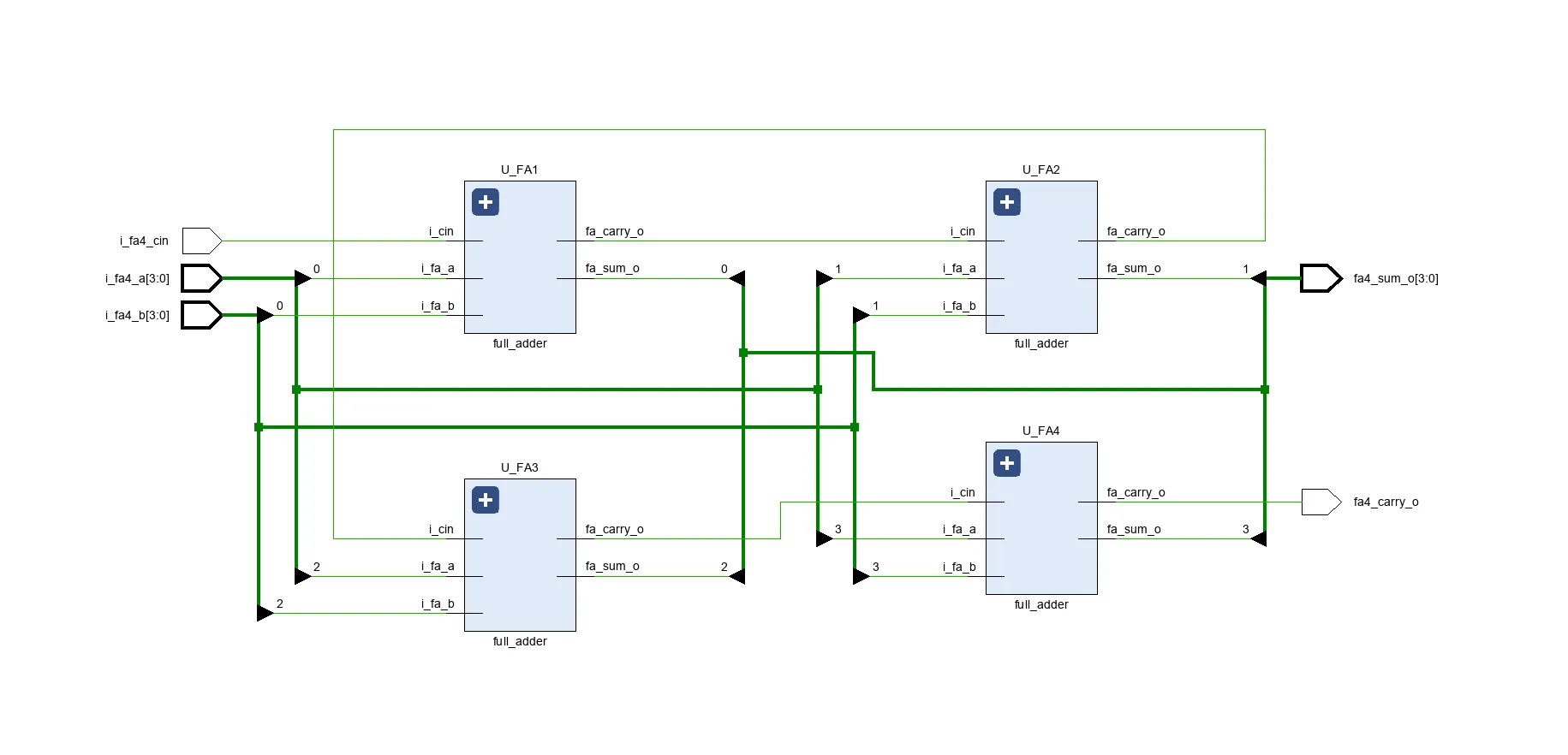
4bit full_adder
4bit full adder는 1bit full adder 4개로 구성된다.
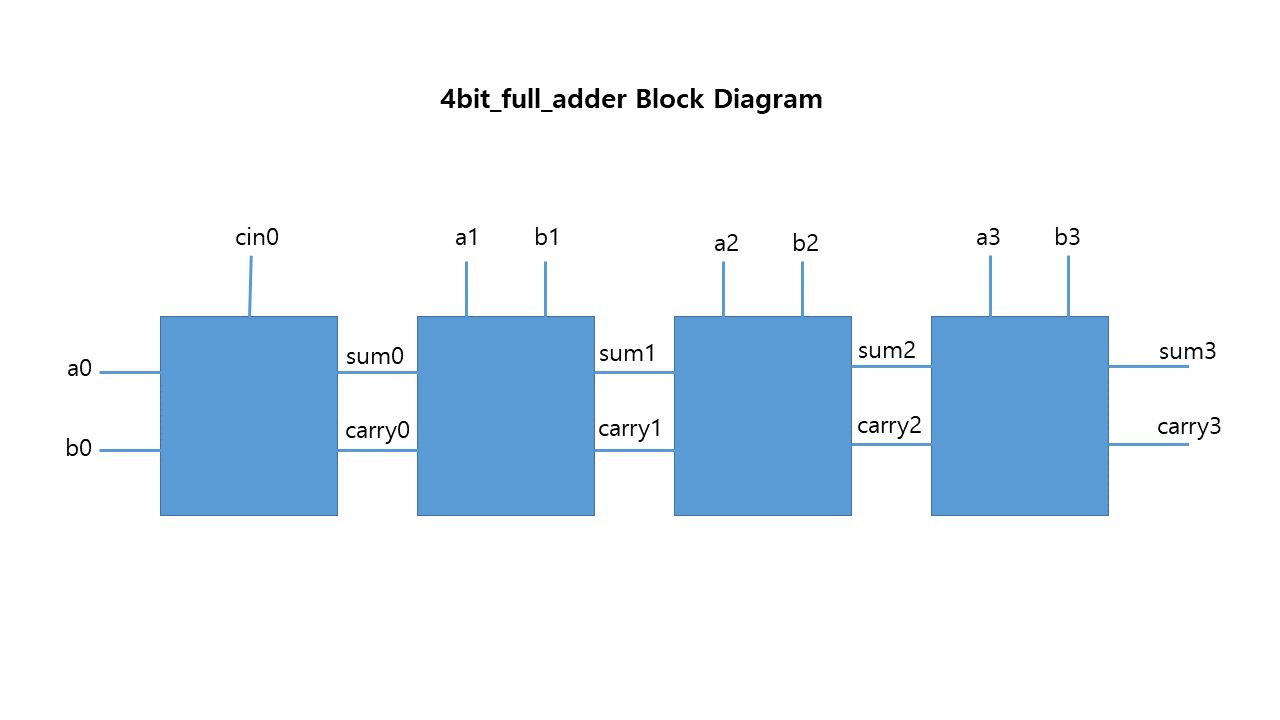
- fullAdder_4bit.v
`timescale 1ns / 10ps
module fullAdder_4bit(
input [3:0] i_fa4_a,
input [3:0] i_fa4_b,
input i_fa4_cin,
output [3:0] fa4_sum_o,
output fa4_carry_o
);
wire [3:0] carry_w;
// assign carry_w[0] = i_fa4_cin;
full_adder U_FA1(
.i_fa_a(i_fa4_a[0]),
.i_fa_b(i_fa4_b[0]),
.i_cin(i_fa4_cin),
.fa_sum_o(fa4_sum_o[0]),
.fa_carry_o(carry_w[0])
);
full_adder U_FA2(
.i_fa_a(i_fa4_a[1]),
.i_fa_b(i_fa4_b[1]),
.i_cin(carry_w[0]),
.fa_sum_o(fa4_sum_o[1]),
.fa_carry_o(carry_w[1])
);
full_adder U_FA3(
.i_fa_a(i_fa4_a[2]),
.i_fa_b(i_fa4_b[2]),
.i_cin(carry_w[1]),
.fa_sum_o(fa4_sum_o[2]),
.fa_carry_o(carry_w[2])
);
full_adder U_FA4(
.i_fa_a(i_fa4_a[3]),
.i_fa_b(i_fa4_b[3]),
.i_cin(carry_w[2]),
.fa_sum_o(fa4_sum_o[3]),
.fa_carry_o(carry_w[3])
);
assign fa4_carry_o = carry_w[3];
endmodule
- RTL Analysis
- testbench.v
`timescale 1ns / 10ps
module tb_fullAdder_4bit();
reg [3:0] i_fa4_a;
reg [3:0] i_fa4_b;
reg i_fa4_cin;
wire [3:0] fa4_sum_o;
wire fa4_carry_o;
fullAdder_4bit dut(
.i_fa4_a(i_fa4_a),
.i_fa4_b(i_fa4_b),
.i_fa4_cin(i_fa4_cin),
.fa4_sum_o(fa4_sum_o),
.fa4_carry_o(fa4_carry_o)
);
initial begin
i_fa4_a = 4'b0000; i_fa4_b = 4'b0000; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0001; i_fa4_b = 4'b0001; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0010; i_fa4_b = 4'b0011; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0101; i_fa4_b = 4'b0011; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1111; i_fa4_b = 4'b0001; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b1111; i_fa4_b = 4'b1111; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1001; i_fa4_b = 4'b0110; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0011; i_fa4_b = 4'b1100; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1010; i_fa4_b = 4'b1010; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0100; i_fa4_b = 4'b1001; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1111; i_fa4_b = 4'b1111; i_fa4_cin = 1'b1;
#10 $finish; // End of simulation
end
endmodule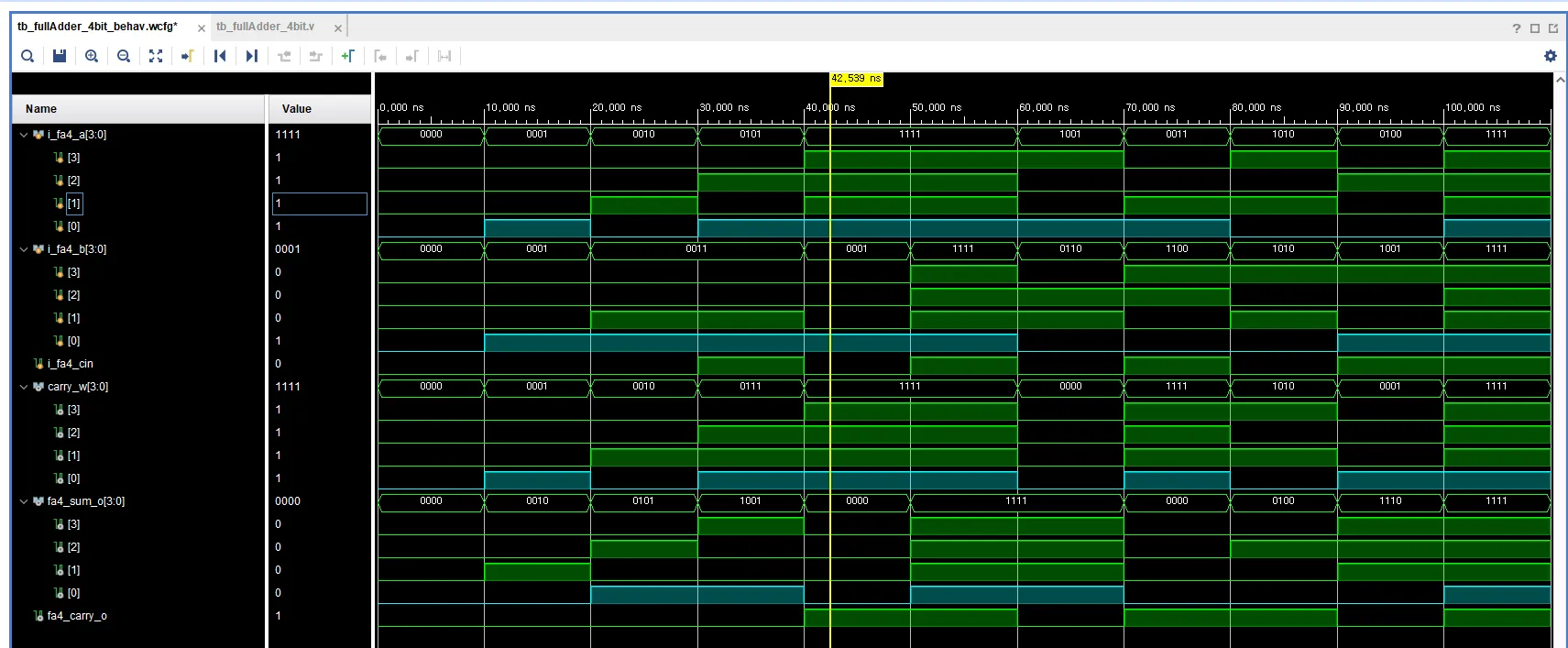
'하만 세미콘 아카데미 8기 > verilog 설계' 카테고리의 다른 글
| 241206 cpu 설계 기초 2 (0) | 2024.12.07 |
|---|---|
| 241205 cpu 설계 기초 (0) | 2024.12.06 |
| 241106 - verilog 기초 3 (+Counter) (0) | 2024.11.07 |
| 241105 verilog 기초 2 (+fnd controller) (0) | 2024.11.07 |
HDL 기반 시스템 반도체 설계 과정
verilog compile 과정
verilog code (sw) -> (1) synthesis -> H/W circuit -> fpga implementation -> bitstream (fpga 등 h/w 회로 파일, xxx.bit)
-> synthesis 과정에서 net list가 생성됨
* net list : 정렬되지 않은 형태의 H/W 정보
(1) synthesis : verilog 코드를 design compiler를 이용해 gate-level netlist로 변환하는 과정
(2) implementation : gate, tr 상태에서의 회로 배치
gate
- gates.v - verilog code
and / nand / or / nor / xor / xnor / not gate 를 연속 할당문(continuous assignment) 으로 구현
`timescale 1ns / 1ps
module gates( // chip name
// port list
input a,
input b,
output y0,
output y1,
output y2,
output y3,
output y4,
output y5,
output y6
);
// circuit architecture
assign y0 = a & b; // and oper
assign y1 = ~ (a & b); // nand oper
assign y2 = a | b; // or oper
assign y3 = ~ (a | b); // nor oper
assign y4 = a ^ b; // xor oper
assign y5 = ~ (a ^ b); // exnor oper
assign y6 = ~ a;
endmodule
- RTL analysis
1) 코드가 gate level로 분석되어 출력되는 것을 확인할 수 있다
2) 보드에 올리기 위한 pin 설정
package pin, I/O std 설정 후 ctrl+s → xdc (constraint file) 생성
- testbench.v
`timescale 1ns / 1ps
module tb_gates();
reg a;
reg b;
wire y0;
wire y1;
wire y2;
wire y3;
wire y4;
wire y5;
wire y6;
gates dut( // dut(design under test, 관용어) -> 시뮬레이션 대상 instance, instanciation
.a(a), // .포트이름(변수)
.b(b),
.y0(y0),
.y1(y1),
.y2(y2),
.y3(y3),
.y4(y4),
.y5(y5),
.y6(y6)
);
initial begin
#00 a = 1'b0; b = 1'b0;
#10 a = 1'b0; b = 1'b1;
#10 a = 1'b1; b = 1'b0;
#10 a = 1'b1; b = 1'b1;
#10 $finish;
end
endmodule- simulation
🚩 verilog 변수 타입
- reg : 값을 저장 가능
- wire : 값을 저장할 수 X
half_adder
half adder는 1bit를 연산할 때 사용된다.
xor gate와 and gate를 이용해 sum과 carry를 출력한다.
- half_adder.v
`timescale 1ns / 1ps
module half_adder(
input wire i_a,
input wire i_b,
output sum,
output carry
);
assign sum = i_a ^ i_b; // 연속할당문
assign carry = i_a & i_b;
endmodule- RTL Analysis
1bit full_adder
full adder는 1bit를 계산시 carry를 받아서 계산한다.
half adder 두개와 carry끼리 연산하는 or gate로 구성된다.
- full_adder.v
`timescale 1ns / 1ps
// full adder
module full_adder(
input i_fa_a,
input i_fa_b,
input i_cin,
output fa_sum_o,
output fa_carry_o
);
wire sum1, carry1, sum2, carry2;
half_adder U_HA1(
.i_a(i_fa_a),
.i_b(i_fa_b),
.ha_sum_o(sum1),
.ha_carry_o(carry1)
);
half_adder U_HA2(
.i_a(sum1),
.i_b(carry1),
.ha_sum_o(sum2),
.ha_carry_o(carry2)
);
assign fa_carry_o = carry1 | carry2;
assign sum = sum2;
endmodule
// half adder
module half_adder(
input i_a,
input i_b,
output ha_sum_o,
output ha_carry_o
);
assign ha_sum_o = i_a ^ i_b;
assign ha_carry_o = i_a & i_b;
endmodule
- RTL Analysis
- testbench.v
`timescale 1ns / 10ps
module tb_adder();
reg i_fa_a;
reg i_fa_b;
reg i_cin;
wire fa_sum_o;
wire fa_carry_o;
full_adder dut(
.i_fa_a(i_fa_a),
.i_fa_b(i_fa_b),
.i_cin(i_cin),
.fa_sum_o(fa_sum_o),
.fa_carry_o(fa_carry_o)
);
initial begin
#00 i_cin = 0; i_fa_b = 0; i_fa_a = 0;
#10 i_cin = 0; i_fa_b = 0; i_fa_a = 1;
#10 i_cin = 0; i_fa_b = 1; i_fa_a = 0;
#10 i_cin = 0; i_fa_b = 1; i_fa_a = 1;
#10 i_cin = 1; i_fa_b = 0; i_fa_a = 0;
#10 i_cin = 1; i_fa_b = 0; i_fa_a = 1;
#10 i_cin = 1; i_fa_b = 1; i_fa_a = 0;
#10 i_cin = 1; i_fa_b = 1; i_fa_a = 1;
#10 $finish;
end
endmodule
4bit full_adder
4bit full adder는 1bit full adder 4개로 구성된다.
- fullAdder_4bit.v
`timescale 1ns / 10ps
module fullAdder_4bit(
input [3:0] i_fa4_a,
input [3:0] i_fa4_b,
input i_fa4_cin,
output [3:0] fa4_sum_o,
output fa4_carry_o
);
wire [3:0] carry_w;
// assign carry_w[0] = i_fa4_cin;
full_adder U_FA1(
.i_fa_a(i_fa4_a[0]),
.i_fa_b(i_fa4_b[0]),
.i_cin(i_fa4_cin),
.fa_sum_o(fa4_sum_o[0]),
.fa_carry_o(carry_w[0])
);
full_adder U_FA2(
.i_fa_a(i_fa4_a[1]),
.i_fa_b(i_fa4_b[1]),
.i_cin(carry_w[0]),
.fa_sum_o(fa4_sum_o[1]),
.fa_carry_o(carry_w[1])
);
full_adder U_FA3(
.i_fa_a(i_fa4_a[2]),
.i_fa_b(i_fa4_b[2]),
.i_cin(carry_w[1]),
.fa_sum_o(fa4_sum_o[2]),
.fa_carry_o(carry_w[2])
);
full_adder U_FA4(
.i_fa_a(i_fa4_a[3]),
.i_fa_b(i_fa4_b[3]),
.i_cin(carry_w[2]),
.fa_sum_o(fa4_sum_o[3]),
.fa_carry_o(carry_w[3])
);
assign fa4_carry_o = carry_w[3];
endmodule
- RTL Analysis
- testbench.v
`timescale 1ns / 10ps
module tb_fullAdder_4bit();
reg [3:0] i_fa4_a;
reg [3:0] i_fa4_b;
reg i_fa4_cin;
wire [3:0] fa4_sum_o;
wire fa4_carry_o;
fullAdder_4bit dut(
.i_fa4_a(i_fa4_a),
.i_fa4_b(i_fa4_b),
.i_fa4_cin(i_fa4_cin),
.fa4_sum_o(fa4_sum_o),
.fa4_carry_o(fa4_carry_o)
);
initial begin
i_fa4_a = 4'b0000; i_fa4_b = 4'b0000; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0001; i_fa4_b = 4'b0001; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0010; i_fa4_b = 4'b0011; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0101; i_fa4_b = 4'b0011; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1111; i_fa4_b = 4'b0001; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b1111; i_fa4_b = 4'b1111; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1001; i_fa4_b = 4'b0110; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0011; i_fa4_b = 4'b1100; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1010; i_fa4_b = 4'b1010; i_fa4_cin = 1'b0;
#10 i_fa4_a = 4'b0100; i_fa4_b = 4'b1001; i_fa4_cin = 1'b1;
#10 i_fa4_a = 4'b1111; i_fa4_b = 4'b1111; i_fa4_cin = 1'b1;
#10 $finish; // End of simulation
end
endmodule'하만 세미콘 아카데미 8기 > verilog 설계' 카테고리의 다른 글
| 241206 cpu 설계 기초 2 (0) | 2024.12.07 |
|---|---|
| 241205 cpu 설계 기초 (0) | 2024.12.06 |
| 241106 - verilog 기초 3 (+Counter) (0) | 2024.11.07 |
| 241105 verilog 기초 2 (+fnd controller) (0) | 2024.11.07 |